Los 5 algoritmos de agrupación en clústeres que los científicos de datos deben conocer
Este post es una traducción del siguiente artículo. Los nombres de los algoritmos los manejaré en inglés. Todos los creditos van a su creador George Seif.
La agrupación en clústeres es una técnica de aprendizaje automático que implica la agrupación de puntos de datos. Dado un conjunto de puntos de datos, podemos usar un algoritmo de agrupamiento para clasificar cada punto de datos en un grupo específico. En teoría, los puntos de datos que están en el mismo grupo deberían tener propiedades o características similares, mientras que los puntos de datos en diferentes grupos deberían tener propiedades o características muy diferentes. La agrupación en clústeres es un método de aprendizaje no supervisado y es una técnica común para el análisis de datos estadísticos que se utiliza en muchos campos.
En Ciencia de datos (Data Science), podemos usar el análisis de agrupamiento para obtener información valiosa de nuestros datos al ver en qué grupos se encuentran los puntos de datos cuando aplicamos un algoritmo de agrupamiento. Hoy, veremos 5 algoritmos de agrupación en clústeres populares que los científicos de datos deben conocer y sus pros y contras.
K-means Clustering (k-medias)
K-Means es probablemente el algoritmo de agrupación en clústeres más conocido. Se enseña en muchas clases de introducción a la ciencia de datos y al aprendizaje automático. ¡Es fácil de entender e implementar en código! Consulte el gráfico a continuación para ver una ilustración.
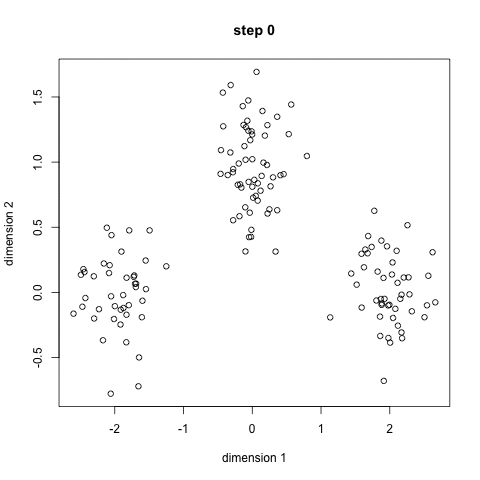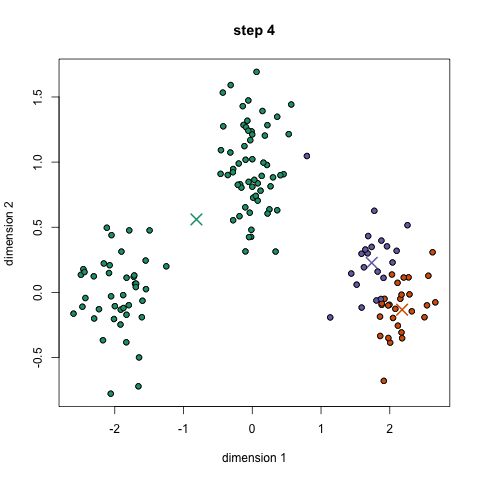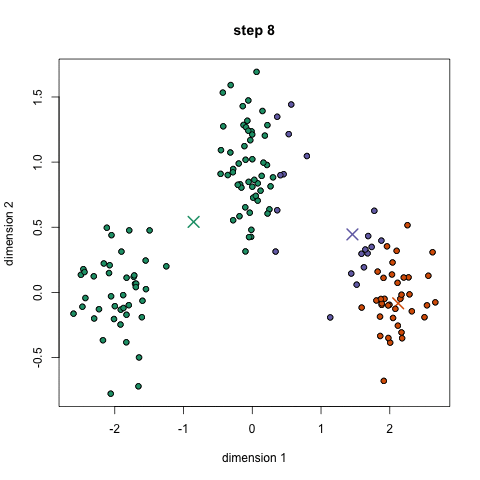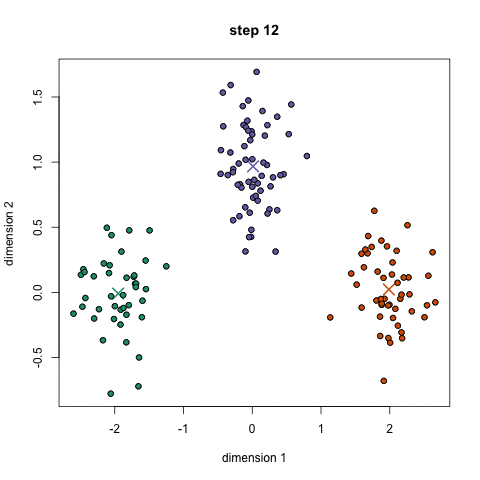
Para comenzar, primero seleccionamos una cantidad de clases o grupos para usar e inicializamos aleatoriamente sus respectivos puntos centrales. Para calcular la cantidad de clases que se deben usar, es bueno echar un vistazo rápido a los datos e intentar identificar cualquier agrupación distinta. Los puntos centrales son vectores de la misma longitud que cada punto vector de datos y son las "X" en el gráfico de arriba.
Cada punto de datos se clasifica calculando la distancia entre ese punto y el centro de cada grupo, y luego clasificando el punto para que esté en el grupo cuyo centro está más cerca de él.
Con base en estos puntos clasificados, recalculamos el centro del grupo tomando la media de todos los vectores del grupo.
Repita estos pasos para un número determinado de iteraciones o hasta que los centros del grupo no cambien mucho entre iteraciones. También puede optar por inicializar aleatoriamente los centros de grupo varias veces y luego seleccionar la ejecución que parece que proporcionó los mejores resultados.
K-Means tiene la ventaja de que es bastante rápido, ya que todo lo que realmente estamos haciendo es calcular las distancias entre los puntos y los centros de los grupos (¡muy pocos cálculos!) Por tanto, tiene una complejidad lineal O(n).
Por otro lado, K-Means tiene un par de desventajas. En primer lugar, debes seleccionar cuántos grupos o clases hay. Esto no siempre es trivial e, idealmente, con un algoritmo de agrupación en clústeres, querríamos que lo averiguara por nosotros porque el objetivo es obtener algo de información a partir de los datos. K-means también comienza con una elección aleatoria de centros de conglomerados y, por lo tanto, puede producir diferentes resultados de conglomerados en diferentes ejecuciones del algoritmo. Por lo tanto, es posible que los resultados no sean repetibles y carezcan de consistencia. Otros métodos de agrupación son más consistentes.
K-Medians (Medians se refiere a la mediana de un conjunto de datos) es otro algoritmo de agrupamiento relacionado con K-Means, excepto que en lugar de volver a calcular los puntos centrales del grupo usando la media, usamos el vector median del grupo. Este método es menos sensible a los valores atípicos (debido al uso de la mediana), pero es mucho más lento para conjuntos de datos más grandes, ya que se requiere ordenar en cada iteración al calcular el vector de la mediana.
Mean-Shift Clustering
Mean-Shift Clustering es un algoritmo basado en ventanas deslizantes (Los algoritmos basados en ventanas son una forma de simplificar el código ya que se crea una ventana que se deslizara sobre una porcion de los datos) que intenta encontrar áreas densas de puntos de datos. Es un algoritmo basado en centroide, lo que significa que el objetivo es ubicar los puntos centrales de cada grupo o clase, que funciona actualizando candidatos para puntos centrales para que sean la media de los puntos dentro de la ventana deslizante. Estas ventanas candidatas luego se filtran en una etapa de posprocesamiento para eliminar duplicados (o ventanas muy parecidas), formando el conjunto final de puntos centrales y sus grupos correspondientes. Consulte el gráfico a continuación para ver una ilustración.
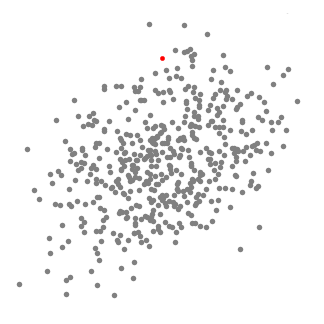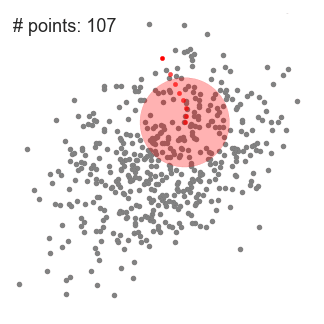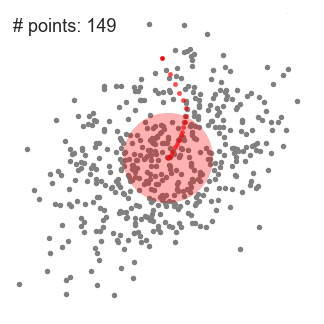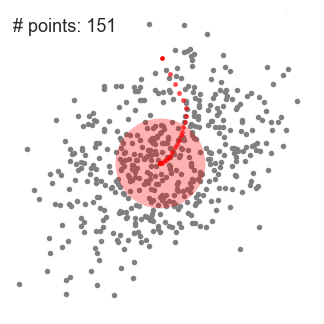
- Para explicar el mean-shift, consideraremos un conjunto de puntos en un espacio bidimensional como la ilustración anterior. Comenzamos con una ventana deslizante circular centrada en un punto C (seleccionado al azar) y que tiene un radio r como núcleo. El mean-shift es un algoritmo de escalada que implica cambiar este núcleo de forma iterativa a una región de mayor densidad en cada paso hasta que converja.
- En cada iteración, la ventana deslizante se desplaza hacia regiones de mayor densidad cambiando el punto central a la media de los puntos dentro de la ventana (de ahí el nombre). La densidad dentro de la ventana deslizante es proporcional al número de puntos dentro de ella. Naturalmente, al cambiar a la media de los puntos en la ventana, se moverá gradualmente hacia áreas de mayor densidad de puntos.
- Continuamos desplazando la ventana deslizante de acuerdo con la media hasta que no haya una dirección en la que un desplazamiento pueda acomodar más puntos dentro del kernel. Mira el gráfico de arriba; seguimos moviendo el círculo hasta que ya no estemos aumentando la densidad (es decir, el número de puntos en la ventana).
- Este proceso de los pasos 1 a 3 se realiza con muchas ventanas deslizantes hasta que todos los puntos se encuentran dentro de una ventana. Cuando varias ventanas deslizantes se superponen, se conserva la ventana que contiene la mayoría de los puntos. Luego, los puntos de datos se agrupan de acuerdo con la ventana deslizante en la que residen.
A continuación se muestra una ilustración de todo el proceso de un extremo a otro con todas las ventanas deslizantes. Cada punto negro representa el centroide de una ventana deslizante y cada punto gris es un punto de datos.

A diferencia de la agrupación de K-medias, no es necesario seleccionar el número de agrupaciones, ya que el desplazamiento de media lo descubre automáticamente. Esa es una gran ventaja. El hecho de que los centros de los clústeres converjan hacia los puntos de densidad máxima también es bastante deseable, ya que es bastante intuitivo de comprender y encaja bien en un sentido naturalmente impulsado por los datos. El inconveniente es que la selección del tamaño (radio) de la ventana “r” puede no ser trivial.
Density-Based Spatial Clustering of Applications with Noise - DBSCAN (Agrupación espacial basada en densidad de aplicaciones con ruido - DBSCAN)
DBSCAN es un algoritmo agrupado basado en densidad similar al mean-shift, pero con un par de ventajas notables. ¡Mira otro gráfico elegante a continuación y comencemos!

- DBSCAN comienza con un punto de datos inicial arbitrario que no se ha visitado. La vecindad de este punto se extrae usando una distancia ε (Todos los puntos que están dentro de la distancia son puntos de vecindad).
- Si hay una cantidad suficiente de puntos (según minPoints [Minpoint es el número mínimo de puntos que consideramos para definir una región densa]) dentro de esta vecindad, entonces comienza el proceso de agrupamiento y el punto de datos actual se convierte en el primer punto en el nuevo grupo. De lo contrario, el punto se etiquetará como ruido (más tarde, este punto ruidoso podría convertirse en parte del grupo). En ambos casos, ese punto se marca como "visitado".
- Para este primer punto en el nuevo grupo, los puntos dentro de su vecindad de distancia ε también pasan a formar parte del mismo grupo. Este procedimiento de hacer que todos los puntos de la vecindad pertenezcan al mismo grupo se repite luego para todos los puntos nuevos que se acaban de agregar al grupo de grupos.
- Este proceso de los pasos 2 y 3 se repite hasta que se determinan todos los puntos en el grupo, es decir, todos los puntos dentro de la vecindad ε del grupo se han visitado y etiquetado.
- Una vez que terminamos con el clúster actual, se recupera y procesa un nuevo punto no visitado, lo que lleva al descubrimiento de otro clúster o ruido. Este proceso se repite hasta que todos los puntos se marcan como visitados. Dado que al final de esto se han visitado todos los puntos, cada punto se habrá marcado como perteneciente a un grupo o como ruido.
DBSCAN presenta grandes ventajas sobre otros algoritmos de agrupamiento. En primer lugar, no requiere un número predefinido de clusters en absoluto. También identifica valores atípicos como ruidos, a diferencia del desplazamiento medio, que simplemente los arroja a un grupo incluso si el punto de datos es muy diferente. Además, puede encontrar grupos de tamaño y forma arbitrarios bastante bien.
El principal inconveniente de DBSCAN es que no funciona tan bien como otros algoritmos cuando los clústeres son de densidad variable. Esto se debe a que la configuración del umbral de distancia y minPoints para identificar los puntos vecinos variará de un grupo a otro cuando la densidad varíe. Este inconveniente también ocurre con datos de muy alta dimensión, ya que nuevamente el umbral de distancia se vuelve difícil de estimar.
Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM) (Agrupación de expectativas-maximización (EM) mediante modelos de mezcla Gaussiana (GMM))
Uno de los principales inconvenientes de K-Means es su uso ingenuo de la media para el centro del grupo. Podemos ver por qué esta no es la mejor manera de hacer las cosas al mirar la imagen a continuación. En el lado izquierdo, parece bastante obvio para el ojo humano que hay dos grupos circulares con diferentes radios centrados en la misma media. K-Means no puede manejar esto porque los valores medios de los grupos están muy próximos entre sí. K-Means también falla en los casos en que los grupos no son circulares, nuevamente como resultado de usar la media como centro del grupo.

Los Gaussian Mixture Models (GMM) nos brindan más flexibilidad que K-Means. Con los GMM asumimos que los puntos de datos tienen una distribución Gaussiana; esta es una suposición menos restrictiva que decir que son circulares usando la media. De esa manera, tenemos dos parámetros para describir la forma de los conglomerados: ¡la media y la desviación estándar! Si tomamos una muestra de dos dimensionnes, esto implicaría que los grupos pueden tomar cualquier tipo de forma elíptica (ya que tenemos una desviación estándar en las direcciones x e y). Por lo tanto, cada distribución gaussiana se asigna a un solo grupo.
Para encontrar los parámetros de Gauss para cada grupo (por ejemplo, la media y la desviación estándar), usaremos un algoritmo de optimización llamado Expectation–Maximization (EM). Eche un vistazo al gráfico a continuación como una ilustración de los modelos Gaussianos que se ajustan a los grupos. Luego, podemos continuar con el proceso de agrupación en clústeres de Expectation–Maximization utilizando GMM.
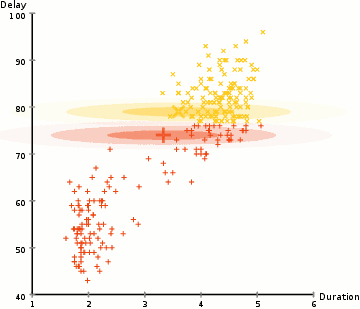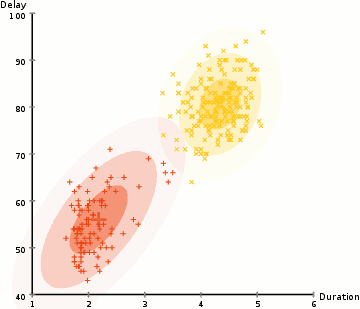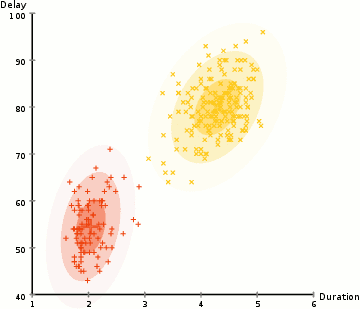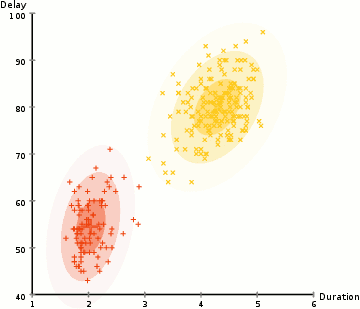
- Comenzamos seleccionando el número de conglomerados (como hace en K-Means) e inicializando aleatoriamente los parámetros de distribución gaussiana para cada conglomerado. También se puede intentar proporcionar una buena estimación de los parámetros iniciales echando un vistazo rápido a los datos. Aunque tenga en cuenta, como se puede ver en el gráfico anterior, esto no es 100% necesario ya que los gaussianos comienzan como muy pobres pero se optimizan rápidamente.
- Dadas estas distribuciones gaussianas para cada grupo, calcule la probabilidad de que cada punto de datos pertenezca a un grupo en particular. Cuanto más cerca está un punto del centro Gaussiano, es más probable que pertenezca a ese grupo. Esto debería tener un sentido intuitivo, ya que con una distribución Gaussiana asumimos que la mayoría de los datos se encuentran más cerca del centro del grupo.
- Con base en estas probabilidades, calculamos un nuevo conjunto de parámetros para las distribuciones Gaussianas de manera que maximizamos las probabilidades de los puntos de datos dentro de los grupos. Calculamos estos nuevos parámetros usando una suma ponderada de las posiciones de los puntos de datos, donde los pesos son las probabilidades del punto de datos que pertenece a ese grupo en particular. Para explicar esto visualmente podemos echar un vistazo al gráfico de arriba, en particular el cluster amarillo. La distribución comienza aleatoriamente en la primera iteración, pero podemos ver que la mayoría de los puntos amarillos están a la derecha de esa distribución. Cuando calculamos una suma ponderada por las probabilidades, aunque hay algunos puntos cerca del centro, la mayoría de ellos están a la derecha. Por tanto, naturalmente, la media de la distribución se acerca más a ese conjunto de puntos. También podemos ver que la mayoría de los puntos están "de arriba a la derecha a abajo a la izquierda". Por lo tanto, la desviación estándar cambia para crear una elipse más ajustada a estos puntos, para maximizar la suma ponderada por las probabilidades.
- Los pasos 2 y 3 se repiten iterativamente hasta la convergencia, donde las distribuciones no cambian mucho de una iteración a otra.
Hay dos ventajas clave de utilizar GMM. En primer lugar, los MMG son mucho más flexibles en términos de covarianza de clústeres que las K-medias; Debido al parámetro de desviación estándar, los grupos pueden adoptar cualquier forma de elipse, en lugar de limitarse a círculos. K-Means es en realidad un caso especial de GMM en el que la covarianza de cada grupo a lo largo de todas las dimensiones se acerca a 0. En segundo lugar, dado que los GMM usan probabilidades, pueden tener múltiples grupos por punto de datos. Entonces, si un punto de datos está en el medio de dos grupos superpuestos, simplemente podemos definir su clase diciendo que pertenece el porcentaje X a la clase 1 y el porcentaje Y a la clase 2. Es decir, los GMM admiten membresía mixta.
Agglomerative Hierarchical Clustering (Agrupación jerárquica aglomerativa)
Los algoritmos de agrupamiento jerárquico se dividen en 2 categorías: de arriba hacia abajo o de abajo hacia arriba. Los algoritmos ascendentes tratan cada punto de datos como un solo grupo desde el principio y luego fusionan (o aglomeran) sucesivamente pares de grupos hasta que todos los grupos se hayan fusionado en un solo grupo que contiene todos los puntos de datos. La agrupación jerárquica de abajo hacia arriba se denomina agrupación aglomerativa jerárquica o HAC (de sus siglas en inglés Hierarchical Agglomerative Clustering ). Esta jerarquía de grupos se representa como un árbol (o dendrograma). La raíz del árbol es el grupo único que reúne todas las muestras, siendo las hojas los grupos con una sola muestra. Consulte el gráfico a continuación para ver una ilustración antes de pasar a los pasos del algoritmo.
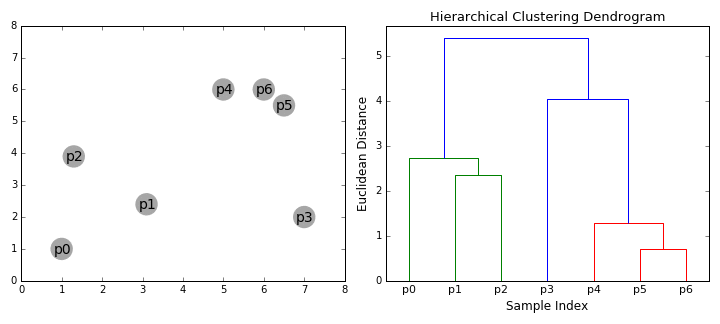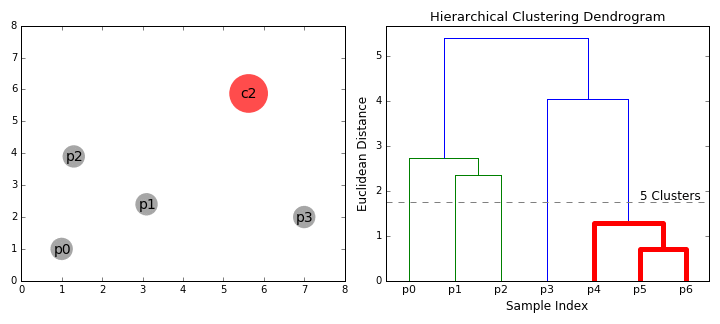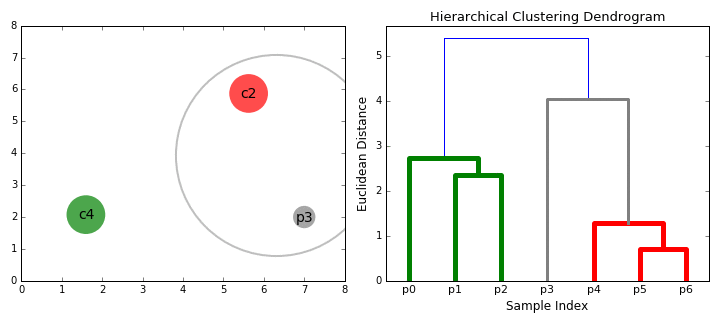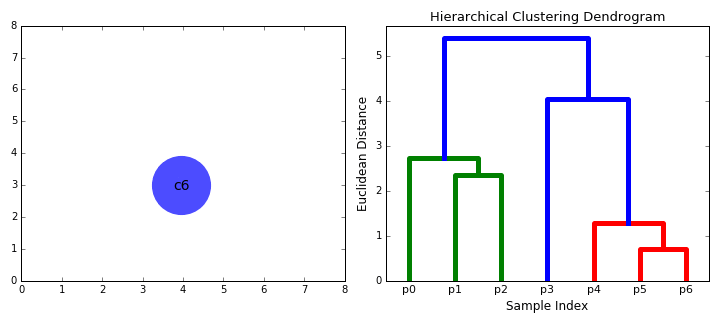
Comenzamos tratando cada punto de datos como un solo grupo, es decir, si hay X puntos de datos en nuestro conjunto de datos, entonces tenemos X grupos. Luego, seleccionamos una métrica de distancia que mide la distancia entre dos grupos. Como ejemplo, usaremos el enlace promedio (average linkage) que define la distancia entre dos grupos como la distancia promedio entre los puntos de datos en el primer grupo y los puntos de datos en el segundo grupo.
En cada iteración, combinamos dos grupos en uno. Los dos conglomerados que se van a combinar se seleccionan como aquellos con el menor vínculo promedio. Es decir, de acuerdo con nuestra métrica de distancia seleccionada, estos dos grupos tienen la distancia más pequeña entre sí y, por lo tanto, son los más similares y deben combinarse.
El paso 2 se repite hasta que llegamos a la raíz del árbol, es decir, solo tenemos un grupo que contiene todos los puntos de datos. De esta manera, podemos seleccionar cuántos clústeres queremos al final, simplemente eligiendo cuándo dejar de combinar los clústeres, es decir, ¡cuándo dejamos de construir el árbol!
El agrupamiento jerárquico no requiere que especifiquemos el número de grupos e incluso podemos seleccionar qué número de grupos se ve mejor ya que estamos construyendo un árbol. Además, el algoritmo no es sensible a la elección de la métrica de distancia; todos tienden a funcionar igualmente bien, mientras que con otros algoritmos de agrupamiento, la elección de la métrica de distancia es fundamental. Un caso de uso particularmente bueno de los métodos de agrupamiento jerárquico es cuando los datos subyacentes tienen una estructura jerárquica y desea recuperar la jerarquía; otros algoritmos de agrupación en clústeres no pueden hacer esto. Estas ventajas de la agrupación jerárquica tienen el costo de una menor eficiencia, ya que tiene una complejidad de tiempo de O(n³), a diferencia de la complejidad lineal de K-Means y GMM.
Conclusiones
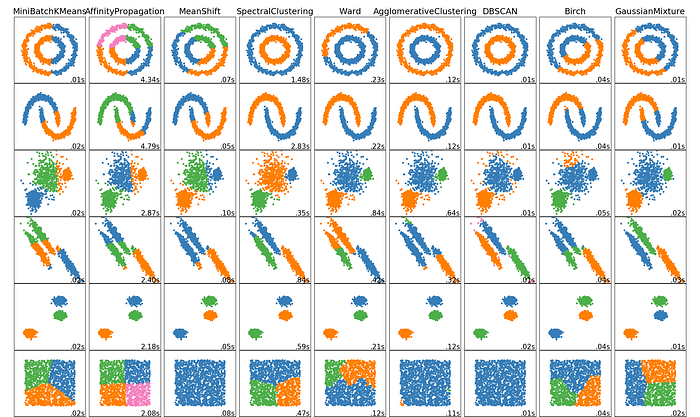
¡Estos son los 5 algoritmos de agrupación en clúster principales que un científico de datos debería conocer! Terminaremos con una visualización impresionante de lo bien que funcionan estos algoritmos y algunos otros, cortesía de Scikit Learn. ¡Es genial ver cómo los diferentes algoritmos se comparan y contrastan con diferentes datos!